

文章目录
Introduction
Natural Language Inference任务介绍
NLI又叫做recognizing textual entailment. 是用来确定两句话是不是蕴含关系.
第一句话作为premise, 第二句话作为hypothesis, 则两句话的三种关系定义如下:
- entailment(如果premise为真, 则hypothesis也必须为真)
- contradiction(如果premise为真, 则hypothesis必须为假)
- neutral(既不是entailment, 也不是contradiction)
Model
Interactive Inference Network(IIN)
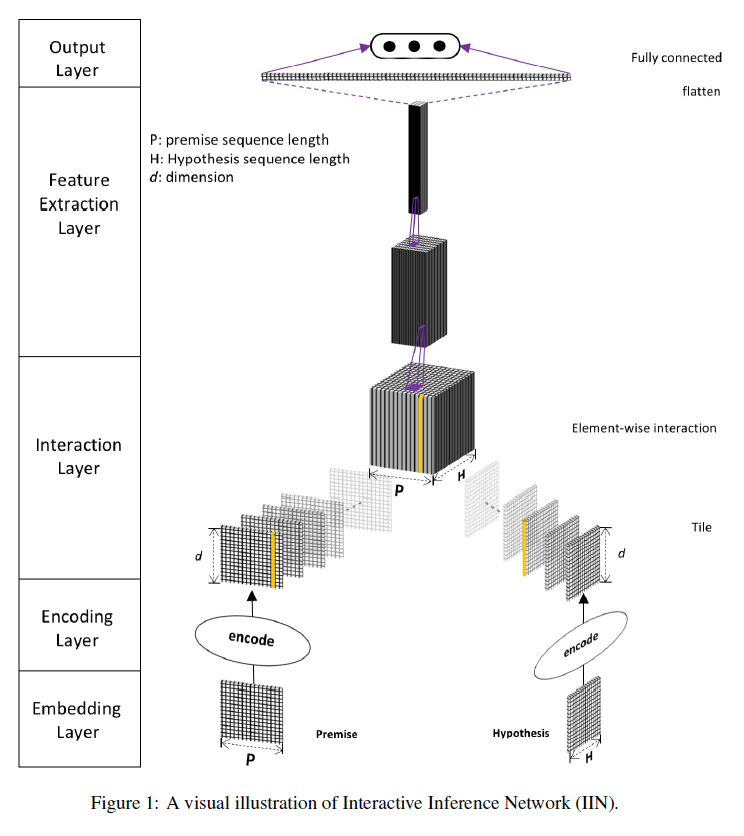
先介绍下基础的IIN
模型主要包括五部分, 每部分都可以用不同的方式实现.
- Embedding Layer: 将词或者短语转换为向量表示, 并构造句子的矩阵表示.
可以直接使用预训练的词向量, 比如word2vec, glove等等.
为了提高效果, 还可以利用词性标注, 命名实体识别等方法获取更多词汇和句法信息. - Encoding Layer: 对Embedding Layer的输出进行编码, 这部分可以选择不同的编码器, 比如BiLSTM, self-attention等等. 不同的编码器可以结合使用来获得更好的句表示.
- Interaction Layer: 生成premise和hypothesis之间的interaction tensor.
Interaction有多种不同的建模方式, 比如计算余弦距离, 点积等等. - Feature Extraction Layer: 解析从Interaction layer获取的语义特征. 这部分作者使用的2-D的CNN
- Output Layer
Densely Interactive Inference Network(DIIN)
进入正题, 介绍DIIN. DIIN的基础结构和IIN是一样的.
Embedding Layer
Embedding部分, 作者使用了word embedding, character feature和syntactical features进行拼接.
word embedding直接用的预训练的GloVe, 注意, 作者在训练时会对词向量进行更新.
character feature是通过一维的卷积来实现的, 卷积后进行max-pooling. 作者指出, character feature有助于解决OOV问题. CNN在premise和hypothesis之间共享权重.
Syntactical feature包含词性标注的one-hot向量和 binary exact match feature.
Encoding Layer
将上层得到的premise表示 P和hypothesis表示 H先通过一个两层的highway network得到 P^ 和 H^作为新的表示.
然后, 通过self-attention layer获取词序和上下文信息. self-attention过程如下:

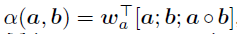
之后,将 P^和 Pˉ拼接并送入fuse date.

用同样的方法得到 H~
Interaction Layer
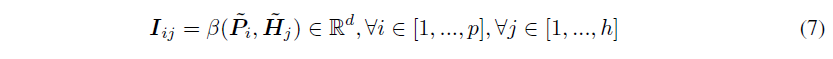
这里 β(a,b)=a∘b, 也就是element-wise product
Feature Extraction Layer
这部分作者将DenseNet作为CNN特征提取器.
另外, 作者在实验时发现batch normalization会延迟收敛, 而且没有提高准确率, 所以他们没用.
在得到Interaction Layer输出后, 先用1x1的卷积降维.注意这部分卷积不用ReLU激活.
假如输入通道数为 k, 输出通道变为 floor(k×η).
接着输入到DenseNet中, 每个DenseNet块包含n层3x3卷积, growth rate为g.
Output Layer
全连接做分类

实验
数据
- SNLI
- MultiNLI
- Quora question pair
参数设置
optimizer: Adadelta( ρ=0.95, ϵ=1e−8)
learning rate: 0.5
batch size: 70
模型不能进一步收敛后, 使用SGD(learning rate=3e-4)继续训练
在每个线性层之前都用了dropout.
word embedding: 300D GloVe 840B
character embedding: 随机初始化 100D
1维的character embedding卷积核设置为5

 京公网安备 11010502036488号
京公网安备 11010502036488号